14.10.17 Using assert() in Embedded Systems
1. assert()
In C++ (and many other languages), assert() is a useful function to find bugs in code during runtime. assert() tests that invariants, preconditions, or postconditions are met at runtime. Basically, assert() is used to make sure that a program is always in a valid state and to find the bug that caused the program to get into an invalid state as early as possible.
In bug-free software, an assert() will never fail and thus it's safe to remove all asserts from bug-free software. For all the mortals of us, we would usually love to keep the asserts active in the code. Just in case there is still a bug that was not caught by all the safety nets we used to get as close as possible to bug-free software.
Debug Build
In a so-called debug build, usually, two changes are made to the build environment: The optimizations are reduced and asserts are enabled. Both lead to larger executables. In the embedded world, this increasing executable size can easily lead to overflowing the available flash memory on the target hardware.
Common Use-Cases for assert() in Embedded Systems
I have basically 3 use-cases for assert() in an embedded system:
- Stopping the program during debugging and showing the point of failure
- Restarting the software when an error condition was detected during runtime
- Persists the point of failure for later reporting, when the software is shipped
2. Observations Made with a Small Example
To illustrate the problem with assert() on embedded hardware, I've tried to collect some numbers. I've used a small example, written in C++, that makes heavy use of modern C++ and implements a Bluetooth LE Service for firmware updates.
The example itself contains 2 asserts, the used library (mostly Header-only) contains 167 asserts. I've used the arm-none-eabi-gcc version of GCC 6.3.1.
First, I've compiled the example with optimization for size (-Os) and asserts disabled (-DNDEBUG). The resulting binary is 17,764 bytes large. That's the anchor point.
Next, I've compiled the example with optimization set to a specific value that should be suitable for debugging (-Og) and asserts enabled. The result has a stunning size of 278,772 bytes. That's more than factor 10! So instead of a µController with 32 kilobytes of flash memory, with the usual desktop definition of a Debug Build, the 512 kilobytes version of the µController is required.
It turns out, that mostly function names account for this huge increase of the executable size.
Implementation of assert
Usually, assert() is implemented as a macro that checks a condition. When this condition is false, the macro passes that condition as text, and the position of the assert as file and line to a function, that prints a message and then calls std::abort() (or similar).
In addition, the GCC implementation passes the value of __PRETTY_FUNCTION__ to that function. __PRETTY_FUNCTION__ evaluates to the full-blown function name of the function that contains the failed assert. That's the reason for the huge amount of required flash memory when asserts are enabled. This happens especially when the asserts are buried deep in nested C++ template code, where full pronounced (with all template parameters) functions names tend to span multiple pages of a large monitor with small fonts.
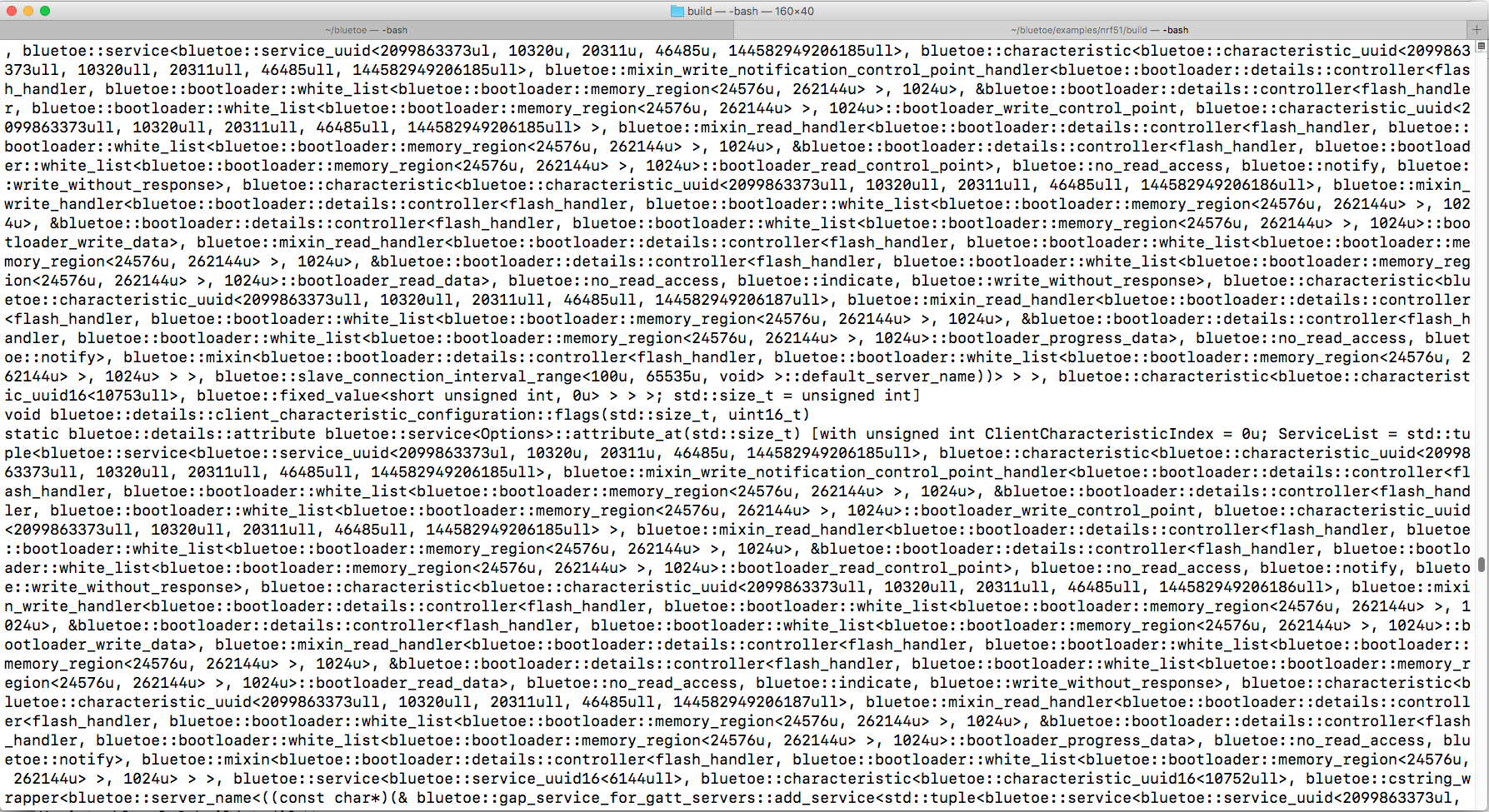{kind=link}
Most of the time, these large function names are very hard to read and not of much help, when it comes to understanding the underlying problem.
This is the (slightly changed) implementation of assert() in GCC:
# define assert(__e) \
((__e) \
? (void)0 \
: __assert_func( \
__FILE__, \
__LINE__, \
__PRETTY_FUNCTION__, \
#__e) \
)
This makes clear, where the huge increase of the required flash comes from: __FILE__ is a text, that contains the source file name of the assert. In most cases, the file name should end up only once in the executable for every file that contains an assert. __LINE__ is a pretty cheap integer. __PRETTY_FUNCTION__ is the full function name and last but not least, #__e is the textual representation of the expression that failed.
More Numbers
I tried some variations of the build parameters and of the implementation of the assert macro, to get a better understand of the costs of the different features. I tried optimized and not optimized build, disabling asserts and used different parameters to the __assert_func() above:
Optimization | Assert Parameters | Resulting Executable Size ------------------------------------------------------------- for size | asserts disabled | (-Os) | (-DNDEBUG) | 17,764 bytes ------------------------------------------------------------- for debugging| asserts fully | (-Og) | enabled | 278,772 bytes ------------------------------------------------------------- for debugging| __FILE__, __LINE__| (-Og) | | 26,892 bytes ------------------------------------------------------------- for debugging| no parameters | (-Og) | | 24,644 bytes ------------------------------------------------------------- for debugging| asserts disabled | (-Og) | (-DNDEBUG) | 23,168 bytes ------------------------------------------------------------- for size | no parameters | (-Os) | | 18.768 bytes ------------------------------------------------------------- for debugging| a 32 bit | (-Og) | hash value | 25,412 bytes ------------------------------------------------------------- for size | a 32 bit | (-Os) | hash value | 19,248 bytes
These numbers are most likely highly dependent on the application. But from the numbers above I read that using asserts would only add a comparatively small amount of 5% addition, required flash memory when reporting failed asserts without any additional information like file names or function names (the 17,764 bytes compared with the 18.768 bytes).
For debugging, an assert without any additional information is quite sufficient. When setting a breakpoint at the assert function that is called from the assert macro (__assert_func), all required information is given by the call stack and debug information that is external to the executable (elf file). There is simply no need to add all this information to the binary for this use-case.
The same goes for the use-case, to restart a program that detected that there is something wrong with the internal state of the program.
3. Hashing __FILE__ and __LINE__
In the last two rows of the table above, a single hash value is passed to the assert function. This hash value has to be calculated at compile time. An interesting blog post from a member of the C++ Usergroup Hannover, Jacek Galowicz, revealed to me, that it is possible to do calculations with string literals in C++.
So even when __FILE__ is used in the version of assert below, the file name will never end up in the executable, because file_and_line_hash<>() is a constexpr function that calculates the hash during compile time.
# define assert(__e) \
((__e) \
? (void)0 \
: __assert_hash_func ( \
assert_hash::file_and_line_hash< std::uint32_t >( \
__FILE__, \
__LINE__ \
) \
) \
)
Now, when a firmware crashes, the assert function (__assert_hash_func) will be called with a hash value. Hash collisions could potentially lead to more than one assert position, that has the very same hash value. But in practice, using a reasonable hash function and a hash value type that is large enough, this shouldn't be an issue.
Just having a hash value, to find the actual line of code, where an assert() failed, a tool is required. That tool has to search the source code for the keyword 'assert' and to calculate the exact same hash algorithm on the found location, as the compiler did during compile time.
The sources for the hash function and the tool, that calculates hash values from source code, can be found on Github.
Using the Program Counter as Hash Value
If practical on a platform, using the program counter as a parameter to the assert function would serve even better to identify the location of a failed assert. In this case, the location of the failed assert has to be retrieved from map files or debug information.
Conclusion
Asserts are not as expensive at it seams (in terms of flash memory usage). When using asserts to detect invalid program states (to restart a program), the additional, required flash memory margin can be as low as 5%.
When there is any mean to persist the information provided by an assert() and/or to feed that information back to the software development, a single hash or program counter value contains nearly all information available.
Especially in modern C++, where full function names tend to be very large, due to the usage of namespaces and nested and recursive templates, __PRETTY_FUNCTION__ results in very large strings of very little value. Maybe, event on desktop platforms, it might be worth having a look at your assert() implementation.